Seven
Moderator
 Din: Ţara Perfectului Simplu
Inregistrat: acum 15 ani
|
|
***
Cred că ar fi necesară o discuţie mai pe larg despre probleme astea.
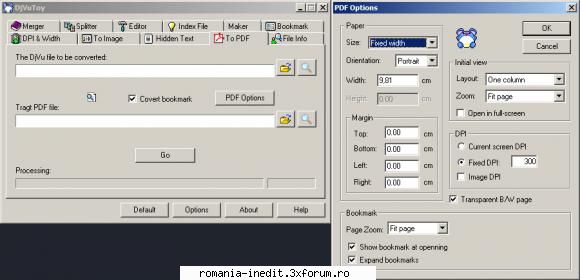
În legătură cu PDF-urile corupte sunt două aspecte:
1. Mai întâi, la marea majoritate a PDF-urilor la care apare mesajul PDF-ul nu se poate deschide, este corupt, acest mesaj este parţial fals. Nu PDF-ul este corupt, ci vizualizatorul de PDF nu înţelege tot sistemul de codare.
Adobe Reader este specialist în astfel de mesaje. El înţelege PDF-urile realizate cu pachetele Adobe, dar dă greş la multe alte PDF-uri realizate cu alte softuri sau imprimante virtuale.
Pentru vizualizarea şi prelucrarea PDF-urilor, eu folosesc PDF-XChange Viewer de la tracker-software.
Multe PDF pe care Adobe nu le vede şi le crede corupte, sunt vizualizate perfect de PDF-XChange Viewer.
Nu e momentul acum să detaliez avantajele PDF-XChange Viewer; le-am scris undeva aici pe forum.
2. Când un vizualizator PDF vede pagini albe în loc de text, nu înseamnă că paginile alea sunt cu adevărat goale. Dintr-un motiv sau altul pot apărea pagini complet albe [goale] sau parţial text, parţial zonă albă. Unele imagini de coperte apar ca şi când s-a vărsat apă peste o pictură în acuarelă şi s-au amestecat culorile. În 99% dintre cazuri este vorba tot de o eroare de interpretare a codurilor.
Astfel de probleme se rezolvă destul de simplu în majoritatea cazurilor astfel: se încarcă respectivul PDF în Abbyy [unde se vor vedea toate paginile corect şi complete] şi se salvează într-un nou PDF care va fi vizualizat corect.
Să revenim la PDF şi DjVu
Nu cred că unul este mai bun şi mai sigur decât celălalt. PDF-ul este folosit de mai mult timp şi eficienţa sa este verificată şi paraverificată, iar DjVu este de dată mai recentă şi are de regulă - o rată de compresie mai mare, fişierele rezultate fiind mai mici.
Mie mi se pare că chestia asta cu fişiere cât mai mici este mai mult o modă decât o necesitate, deoarece dispunem de HDD-uri din ce în ce mai mari. Cred că e doar o chestie de modă, aşa cum a fost moda telefoanelor mobile. Iniţial au apărut cărămizile, apoi era cool să ai un telefon cât mai mic cu putinţă; moda a trecut, iar acum este cool să ai un telefon cât o ţiglă de Jimbolia.
Dar să revenim la fişiere DjVu şi PDF.
Este la modă să avem fişiere cât mai mici, deşi HDD-urile din ziua de azi sunt imense. Păi trebuie să fim conştienţi că cu cât un fişier este mai mic, cu atât va conţine mai puţine informaţii.
Pe de altă parte se pune întrebarea ce dorim să facem cu fişierul [PDF/DjVu] respectiv? Dacă vrem doar să-l folosim pentru confruntarea OCR-ului pe timpul corecturii este suficient şi un fişier mic, dar nu totdeauna. Dacă dorim ca din acest fişier să extragem un OCR pe care apoi să-l corectăm lucrurile se schimbă şi un fişier de 1-2 Mb s-ar putea să fie complet inutil.
De ce fişiere gray/color şi nu AN [alb-negru]?
O imagine color are mii de nuanţe şi se pot deosebi detalii pe zone de imagine de aceeaşi culoare dar de nuanţe diferite.
O imagine grayscale are cel puţin 16 nuanţe de gri, dar de cele mai multe ori cca 48.
Imaginaţi-vă imaginea scanată a unei pagini dintr-o carte care nu se deschide bine. În zona cotorului imaginea este întunecată: într-o imagine gray/color se vor observa detaliile, adică se poate citi textul chiar dacă toată zona cotorului este mai întunecată.
Dar într-o imagine AN [alb-negru]? Păi toate informaţiile se reduc la două valori: este informaţie [culoare] = negru sau nu este informaţie [culoare] = alb. Toate detaliile mai delicate din zona cotorului cărţii prost scanate se duc pe apa sâmbetei, iar noi vom avea o imagine cu text ilizibil. Da, dar avem un fişier mic; bine, bine! Şi la ce ne foloseşte?
Nu neg că există tehnologie de scanare avansată care poate face o scanare în alb-negru de înaltă calitate, dar nu e cazul scanerelor noastre personale.
Soluţia este ca de regulă să păstrăm salvate fişiere gray/color, şi doar în cazuri de scanare perfectă să salvăm în AN.
Pe de altă parte lucrurile au evoluat şi la acest moment se pot obţine cu ABBYY fişiere gray/color PDF sau DjVu destul de mici
de câţiva MB. Nu vom avea un DjVu AN ne-Searchable de 1,5 Mb ca cel obţinut cu DjVuToy, dar putem obţine cu ABBYY un PDF gray Searchable de 5-6 Mb, în care imaginea literelor este la rezoluţie maximă şi conţine şi substratul OCR, astfel că oricând poate fi încărcat în Abbyy şi se extrage OCR-ul ca din scanarea iniţială.
Am menţionat aici despre fişierul PD3. Este vorba de un PDF gray Searchable în care există următoarele straturi:
primul strat este imaginea literelor din pagină care rămâne la rezoluţia iniţială.
al doilea strat este imaginea fundalului paginii, adică a texturii hârtiei la acest PDF rezoluţia de fundal este condensată foarte tare, de unde rezultă şi mărimea mică a fişierului;
al treilea strat, care nu se vede deşi există este stratul OCR, astfel că putem extrage fragment de text OCR direct din PDF.
De ce-l numesc eu PD3? Pentru că este un fişier PDF şi nu unul PDF/A, iar pentru obţinerea lui se setează o opţiune care are numărul 3; vedeţi detalii în postarea mai sus menţionată.
Fac o comparaţie, care poate părea aiurea. Exisă un material textil
cu multe găurele
care se numeşte
a, da, mi-am amintit: dantelă.
Hai să luăm ca exemplu o rochie din dantelă!... Deci rochia din dantelă este comparabilă cu imaginea unei pagini.
Partea de deasupra a rochiei este dantela, aşa cum în PDF imaginea de deasupra este imaginea literelor, iar sub dantelă se află un alt material mat [o dublură sau cum se spune
], aşa cum în PDF avem aveam imaginea de fundal, adică imaginea texturii hârtiei.
Practic într-un PD3 se văd foarte bine detaliile dantelei, deci ale literelor, şi mai puţin bine dublura de sub dantelă. Şi dacă-mi permiteţi să merg mai departe cu idioata comparaţie, OCR-ul ar fi corpul fetei îmbrăcată în rochie. Corpul nu se vede [presupunem prin absurd că rochia este lungă şi plină], dar el există chiar dacă nu se vede.
Concluzie:
Părerea mea personală: salvaţi PDF + DjVu gray/color cu ABBYY. Acel PD3 de care am făcut vorbire este de multe ori chiar mai mic decât DjVu.
Şi da: se poate încărca în ABBYY un DjVu pentru a salva mai apoi un PDF, dar şi invers, se poate încărca un PDF şi se poate obţine un DjVu; condiţia este ca PDF-ul, respectiv DjVu iniţial să aibă o rezoluţie decentă. Dacă este prea comprimat şi redus ca rezoluţie, rezultatul obţinut nu va fi deloc mulţumitor.
_______________________________________
Oameni şi popoare îşi cată libertatea; după ce-o obţin, îşi caută stăpân.
| TORENTE | Tăunul | ROCAMBOLE+ | FLORIS | VRACIU | Victor HUGO | J.F. COOPER | PAPILLON | POLDARK |
| Dictionare Lba RO | | Gramatica RO | D. Stănoiu | Zaharia STANCU | H.Y. STAHL | V.CORBUL & E.BURADA |
| Ultimul regat | Millennium | Shantaram | Pearl BUCK | Anchee MIN | Amy TAN | C. LÄCKBERG | Ph.GREGORY |
| Extraterestrii şi Intraterestrii | RUFOR | Demonul Roşu | Vraja milioanelor | Cărţi audio |
|
|